Introducción al aprendizaje automático
Introducción
El aprendizaje automático es la disciplina cuyo foco es la construcción y el desarrollo de algoritmos que aprenden automáticamente a partir de un conjunto de datos.
Una característica del aprendizaje automático es que los algoritmos se diseñan para ser generales, no para un conjunto de datos concreto.
El aprendizaje automático se divide en tres grandes ramas:
Aprendizaje supervisado: Consiste en los datos de entrada y su salida correspondiente y el objetivo es encontrar una función que mapee nuevas entradas con su salida correspondiente.

Aprendizaje no supervisado: Consiste en el descubrimiento de conceptos. A partir de datos que no están etiquetados buscar las características comunes de estos datos.
Se tienen, únicamente, ejemplos de entrada sin salida correspondiente y el sistema ha de encontrar la estructura que define dichos datos y/o la relación entre los mismos.
Aprendizaje por refuerzo: Consiste en un algoritmo que tiene que realizar una tarea (o serie de tareas) y que encuentra la forma más adecuada de realizarlas experimentando y/u observando e interpretando la información del entorno (feedback). Se suele trabajar con acciones y sus recompensas, encontrando para cada estado la acción que maximice la recompensa recibida.
Esta división no es estricta, ya que un sistema puede aglutinar varias características de los tipos de aprendizaje mencionados.
Aprendizaje supervisado
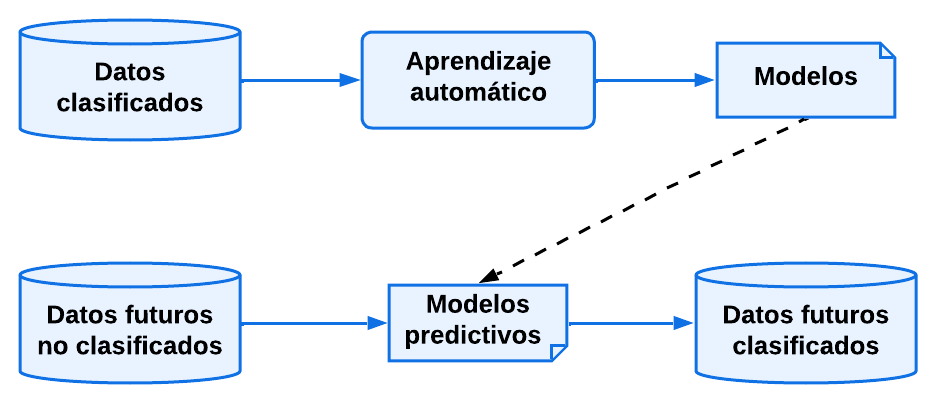
El objetivo del aprendizaje supervisado es predecir eventos futuros en base a eventos pasados.
Su propósito es generar un modelo a partir de un conjunto de datos etiquetados con el fin de realizar predicciones sobre nuevos datos.
Los problemas básicos del aprendizaje supervisado son:
Clasificación: cuando la salida es discreta. Cada uno de los posibles valores de salida es una clase y el objetivo es clasificar a qué clase pertenece una entrada que no hayamos visto.
Regresión: cuando la salida es continua, una función de regresión modela la relación entre las variables de forma continua.
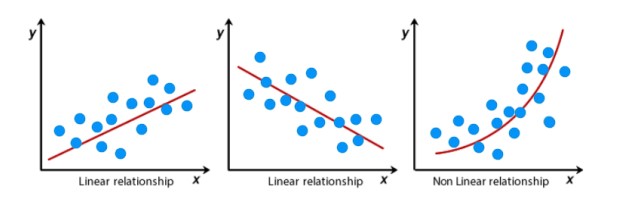
Etapas del aprendizaje supervisado
Selección y preprocesamiento de los datos
Los datos de entrada no siempre están preparados para poder entrenar un modelo.
El conjunto de datos debe proporcionar la cantidad, estructura y formato que se adapte al modelo y nos ayude a alcanzar el objetivo de aprendizaje.
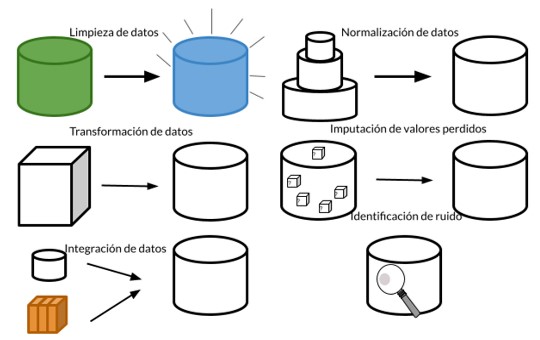
Limpieza de datos e imputación de valores perdidos
Valores perdidos
Cuando dentro de un conjunto de datos, existen instancias que no tienen valor para todas las características.
Cuando esto sucede podemos:
Eliminar la instancia, si el % de datos que falta es mayor que
Reemplazar el dato que falta por un valor:
Sustituir por cero, aunque no siempre es la mejor opción porque se puede producir una subestimación.
Sustituir por un valor probabilístico (media, moda...).
Inferir el dato a partir de otros.
Eliminar instancias duplicadas
Las instancias duplicadas son aquellas que tienen exactamente los mismo valores en todas sus variables.
Transformación de datos
Dentro de las técnicas de transformación encontramos el suavizado, la construcción de características, la agregación, la normalización, la discretización y la generalización.
Normalización de datos
Lo ideal es poder expresar todos los atributos en las mismas unidades de medida o en la misma escala o rango.
La normalización de los datos se realiza para que todos los atributos tengan los mismos rangos de valores de cara a su uso en operaciones matemáticas.
Integración de datos
La importancia de la integración radica en que permite la combinación de datos de diversas fuentes en una sola.
Esto mejora la calidad de los datos y el rendimiento.
Las iniciativas de integración de datos suelen utilizarse para crear almacenes de datos (Data Warehouse), cuyo objetivo principal es proporcionar una mayor comprensión del rendimiento de una organización y mejorar la toma de decisiones.
Identificación de ruido
Es un proceso que identifica datos fuera de lo normal (outlier) y los corrige.
La repetición de los datos puede hacer que un outlier “no lo parezca”, de ahí la importancia de limpiar los datos de posibles duplicidades.
Los outliers pueden llevar a errores sobre todo en algoritmos no supervisados como el clustering, pues podría detectar un “nuevo grupo” formado por valores atípicos.
Reducción de los datos
Cuando la dimensión de los datos es muy alta, resulta muy complejo resolver el problema que surge a la hora de entrenar un algoritmo de aprendizaje automático.
La reducción de datos comprende el conjunto de técnicas empleadas para obtener una representación reducida de los datos originales.
Técnicas de representación reducida de los datos en base a:
Selección de características: su objetivo es encontrar un conjunto mínimo de atributos.
Selección de instancias: elegir el mejor subconjunto de la totalidad de los datos disponible.
Discretización: reducir el número de valores posibles de los atributos.
Agrupación de atributos/instancias: nuevos atributos o instancias cuyo valor semántico agrupa a otros elementos.
Representación de los datos
La representación de los datos de entrada y salida se realiza normalmente en forma de un vector, array que contiene las características de la entrada, y las etiquetas de clase de la salida.
Un número alto de características puede aumentar el tiempo de entrenamiento y conducir a errores en la etapa predicción.
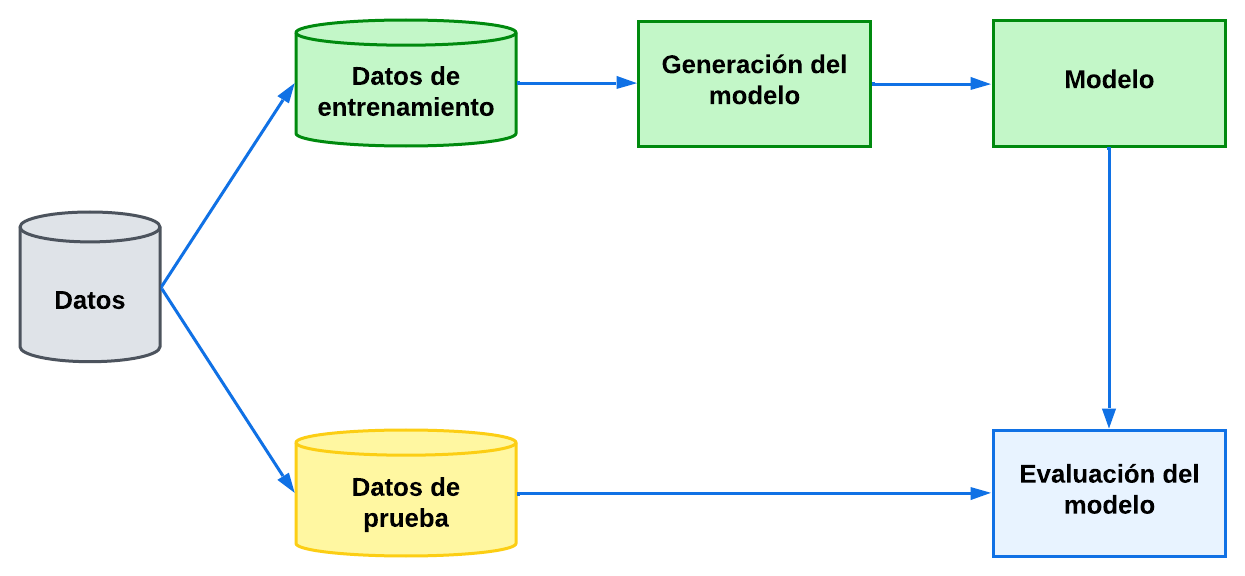
Generación del Modelo
Se debe elegir el algoritmo de aprendizaje y el conjunto de datos de entrenamiento a utilizar. La naturaleza de cada uno puede cambiar y es necesario realizar ajustes de parámetros con el fin de asegurarse de que el algoritmo funcione bien.
Validación de los datos
El modelo generado durante el aprendizaje podrá clasificar nuevos datos que introduzcamos para su clasificación, pero para que esto nos de una cierta seguridad, debemos evaluar la precisión del sistema con datos diferentes a los usados en el entrenamiento.
La validación del modelo permite medir su capacidad de predicción de la clase de nuevas instancias que le lleguen en un futuro.
Modelos básicos de aprendizaje supervisado
Redes Neuronales Artificiales
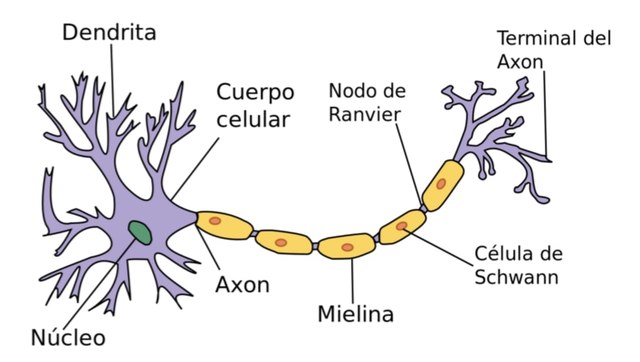
Las redes neuronales artificiales son sistemas de mapeos no lineales cuya estructura se inspira en el funcionamiento del sistema nervioso humano.
Las neuronas son células eléctricamente excitables que procesan y transmiten información mediante señales tanto eléctricas como químicas. Las neuronas se conectan entre sí para formar redes neuronales y su morfología está particularmente adaptada a este propósito.
Las redes neuronales se caracterizan por:
Procesamiento paralelo.
Memoria distribuida.
Adaptabilidad al entorno.
Modelo computacional
A nivel computacional, en una RNA (Red de Neuronas Artificial) los componentes individuales son las neuronas artificiales y la conexión entre ellas.
Funcionamiento informático:
Una neurona artificial tiene varias entradas y una única salida.
Los enlaces ponderados unen la salida a las entradas de otras neuronas.
Los pesos en los enlaces indican la relevancia de esa entrada a la neurona.
Puede existir un umbral de excitación.
Tarea de aprendizaje → ajuste de los pesos.
Ejemplo de estructura de una red típica neuronal:
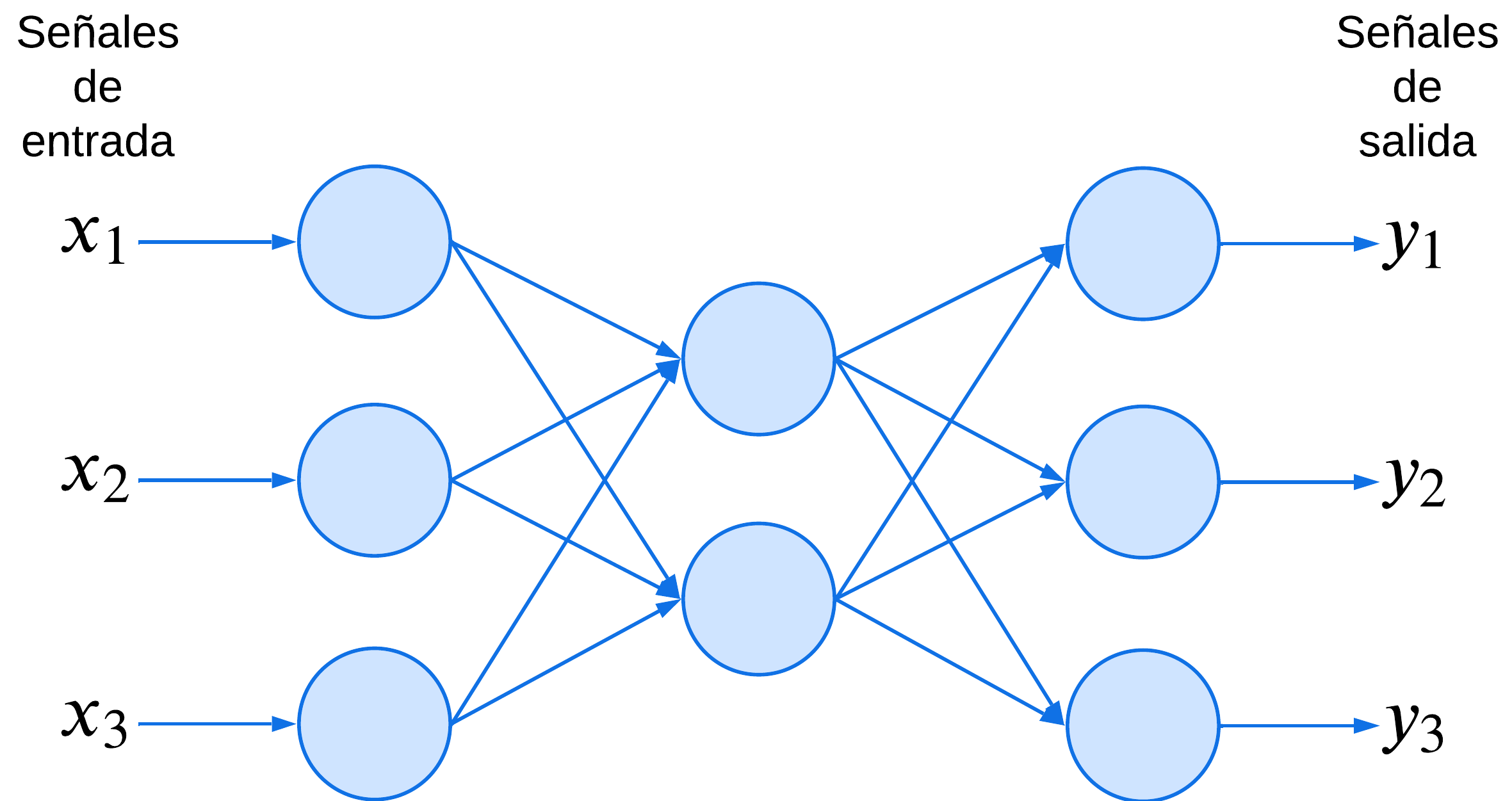
Cada neurona artificial está definida por los siguientes componentes:
Conjunto de entradas:
El conjunto de pesos adaptativos correspondiente a cada entrada:
Un umbral:
Una función de activación:
Una salida:
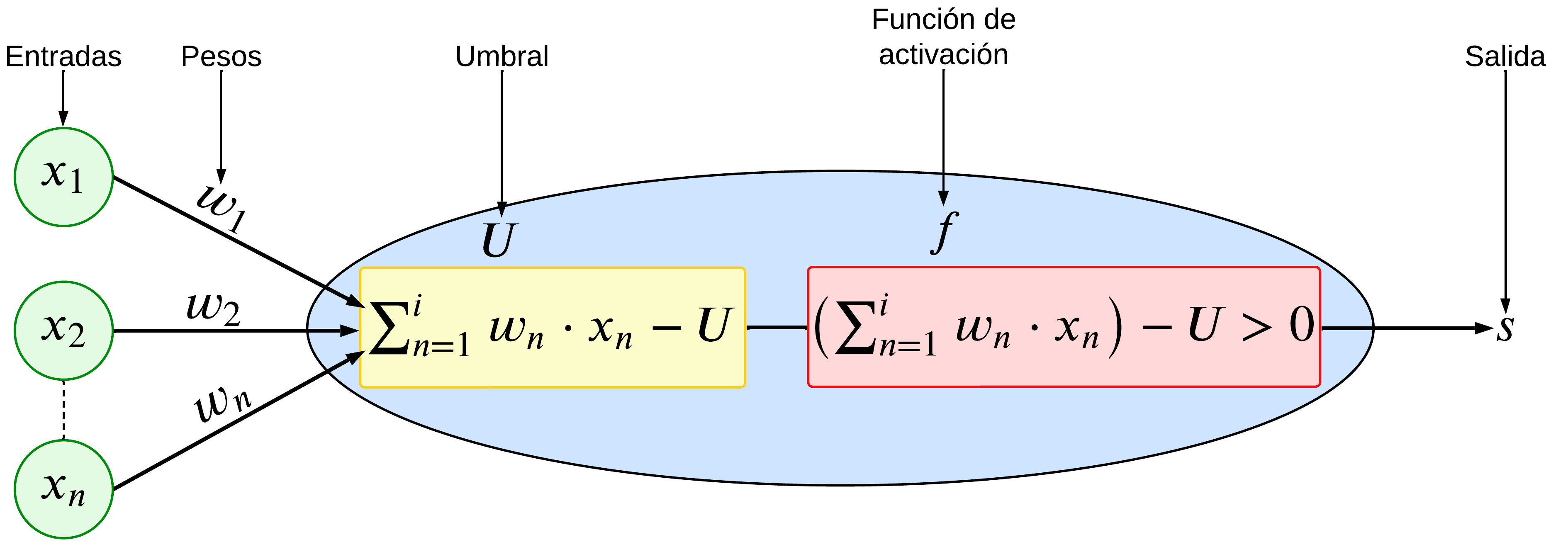
Las entradas del modelo
El conjunto de pesos adaptativos
El umbral
La entrada modificada por el conjunto de pesos junto con el umbral se suele agregar mediante un sumatorio antes de ser utilizada en la función de evaluación. En la figura, esto se representa con una caja etiquetada con el sumatorio
Arquitecturas
Existen diferentes arquitecturas:
Perceptrón simple
La red neuronal artificial más simple es el perceptrón.
El perceptrón simple funciona como un clasificador binario, pudiendo solo discriminar dos clases.
Ejemplo: Si la neurona se activa, el ejemplo es positivo, si no, es negativo.
La función de salida puede ser: signo, función lineal, función escalón, etc.
Ejemplo: La salida
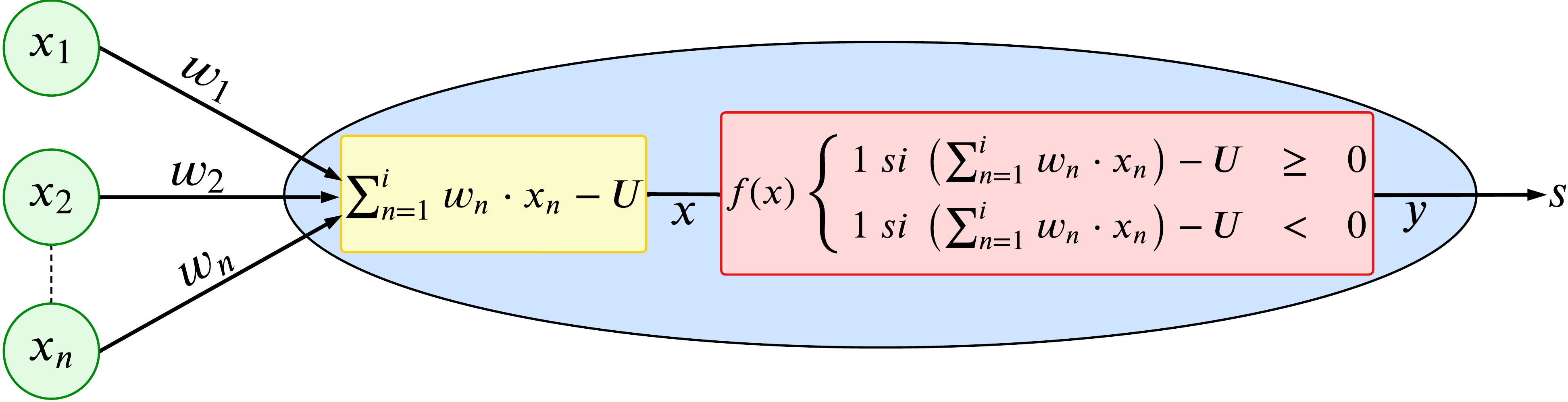
Perceptrón Multicapa
El perceptrón simple emula el comportamiento de una neurona. Sin embargo, la funcionalidad de una neurona (artificial o biológica) es relativamente limitada. La verdadera funcionalidad de las neuronas aparece cuando se combinan en una red, ya que puede exhibir comportamientos mucho más complejos.
Partiendo de esta premisa y después de haber comprobado las limitaciones del perceptrón simple, se propuso el perceptrón multicapa como modelo de red multi-neurona capaz de aprender funciones no lineales.
Las principales características del perceptrón multicapa son:
Tiene múltiples capas de neuronas.
La salida de cada neurona se conecta con todas las neuronas de la siguiente capa.
Las neuronas de la primera capa tienen únicamente como función el propagar las entradas a la primera capa intermedia.
El conjunto forma un grafo dirigido acíclico en el que la información siempre se propaga hacia adelante.
La última capa puede contener tantas neuronas como se quiera, aunque generalmente se usa una neurona por clase si el problema es de clasificación, donde la neurona de salida cuyo valor de salida sea más alto determina a qué clase pertenece la entrada.
|
– Arquitectura de la red:
• Número de capas. • Número de neuronas. • Conexiones entre neuronas. – Función de activación: • Función signo. • Función escalón. • ... – El algoritmo de aprendizaje debe determinarse principalmente por la regla de aprendizaje para ajustar los pesos. |  Perceptrón multicapa |
Redes Bayesianas
Las Redes Bayesianas son redes que emplean la teoría de probabilidad bayesiana para representar en un grafo dirigido acíclico las dependencias entre sus variables aleatorias.
El método bayesiano más aplicado es Naive Bayes, un algoritmo que funciona con atributos categóricos, dado que el cálculo de la probabilidad sólo puede realizarse en dominios discretos.
Funcionamiento
Partimos de un conjunto de información a priori, donde a partir de un conjunto de entrenamiento calculamos las probabilidades condicionales de los diferentes estados discretos.
Después, se realiza el calculo de probabilidades a posteriori, donde a partir de la medición actual, calculamos probabilísticamente el estado en el que nos encontramos.
K-Nearest Neighbor (K - Vecinos Cercanos)
Este tipo de aprendizaje usa una función de densidad de probabilidad y es usado para predecir la clase a la que pertenece una instancia en base a la clasificación de las instancias más cercanas.
Dado que el conjunto de entrenamiento es obtenido en tiempo de ejecución y cambia con cada nueva clasificación, este método es considerado no paramétrico.
Los métodos pueden diferir en relación con:
La métrica de distancia utilizada.
El número de instancias usadas.
Los mecanismos de ponderación de votos.
El uso de algoritmos eficientes para encontrar las instancias más cercanas (tales como KD-Tree, Ball-Tree y Brute-Force).
Algunos de los principales inconvenientes del método son:
Altos requisitos de almacenamiento.
Baja eficiencia en la respuesta de predicción.
La precisión puede verse afectada por el ruido.
K-Means (K-medias)
El algoritmo de k-medias consiste en separar el espacio de representación en k regiones, denominadas regiones de Voronoi.
Cada región queda definida por un centroide que suele definirse como la media de los puntos del cluster, de tal manera que todos los puntos de una misma región están a menor distancia de ese centroide que de los demás.
Las regiones de Voronoi están separadas por hiperplanos perpendiculares al segmento que une cada par de centroides de regiones adyacentes y equidistantes a dichos centroides., que actúan como separador entre regiones.

El número de clusters
Encontrar los centroides óptimos bajo una métrica determinada es un problema complejo. Sin embargo, existen métodos heurísticos que permiten alcanzar óptimos locales de forma eficiente. El proceso
A este algoritmo se le denomina algoritmo de Lloyd, y consiste en ir moviendo los centroides en el espacio de representación de manera que la métrica vaya mejorando con cada iteración. La métrica más utilizada es minimizar la siguiente función:
Donde:
Es decir, la métrica consiste en minimizar la suma de la distancia de cada punto a su centroide más cercano.
El algoritmo de Lloyd es un algoritmo iterativo que consta de dos pasos, la asignación de ejemplos a un centroide y la actualización de los centroides.
Proceso del algoritmo k-Means
Se elige el valor de
Para cada punto, se le asigna el cluster cuyo centroide sea el más cercano.
Una vez asignados todos los puntos a un cluster, se recalcula el centroide como la media de todos los puntos del clúster.
Este proceso se repite hasta que ningún punto cambia de cluster entre dos iteraciones.
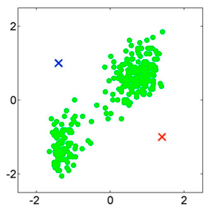
Ejemplo:
Partimos de una población sin asignar y
Colocamos los centroides al azar:
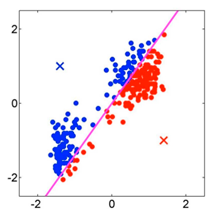
Asignamos los puntos a cada centroide más cercano para identificar a qué cluster pertenecen, para ello, se traza la perpendicular a la línea recta que une los centroides para ambas regiones de Voronoi:
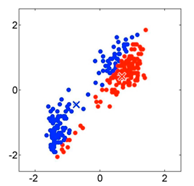
Se recalculan los centroides, que pasan a ser la media de los puntos de su clusters correspondiente:
Volvemos a asignar los puntos a cada centroide más cercano del mismo modo que en el punto 2:
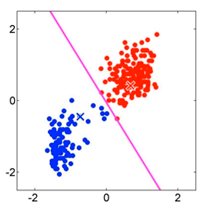
Se vuelven a recalcular los centroides del mismo modo que en el punto 3:
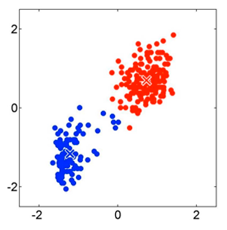
Volvemos a asignar los puntos a cada centroide más cercano del mismo modo que en el punto 2:
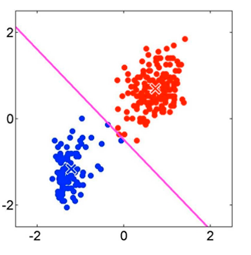
Este proceso se repite hasta que ningún punto cambia de cluster entre dos iteraciones.
Máquinas de vector soporte
Las máquinas de vectores de soporte (SVM, del inglés Support Vector Machine), tienen el propósito de transformar un conjunto de datos de una dimensión
Son consideradas como una extensión del perceptrón. La diferencia radica en que el algoritmo del perceptrón busca minimizar los errores de clasificación, mientras que en las SVM el objetivo de optimización es maximizar el margen de diferencia entre dos grupos.
Busca encontrar un hiperplano que divida el espacio en dos partes, maxificando la diferencia.
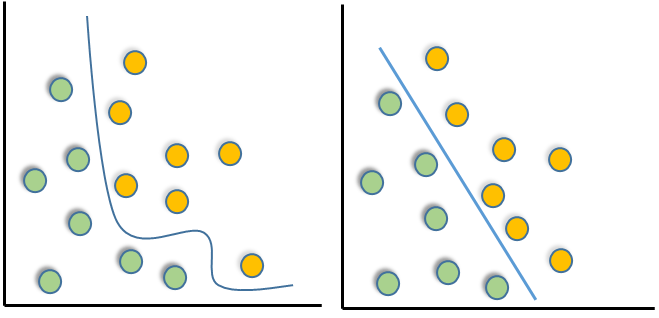
Árboles de decisión
Los árboles de decisión consisten en trazar todos los caminos posibles considerando la importancia de cada atributo, utilizando particiones recursivas para clasificar los datos.
Los arboles de decisión se componen de:
Nodos hoja, que se etiquetan con una de las posibles clases.
Nodos internos, que corresponden a un atributo y cada rama descendiente corresponde a un valor del atributo.
Ejemplo:
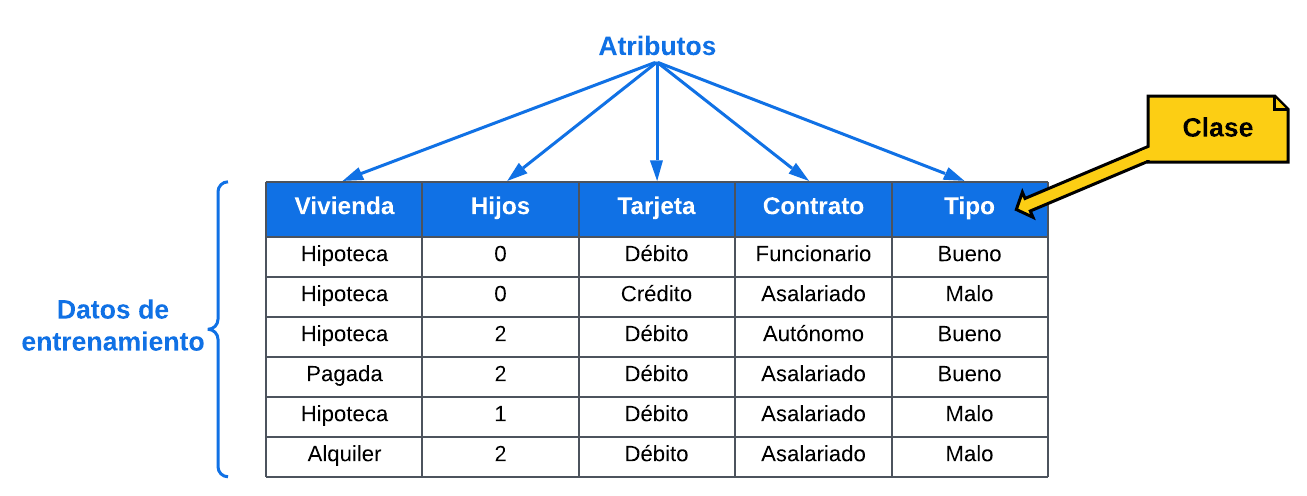
Una entidad bancaria decide clasificar a sus clientes entre buenos y malos en función de retrasos en pagos en el pasado e índice de morosidad. Para facilitar a los agentes de banca el proceso de concesión de créditos, se quiere aprender qué factores influyen en si un cliente será bueno o malo.
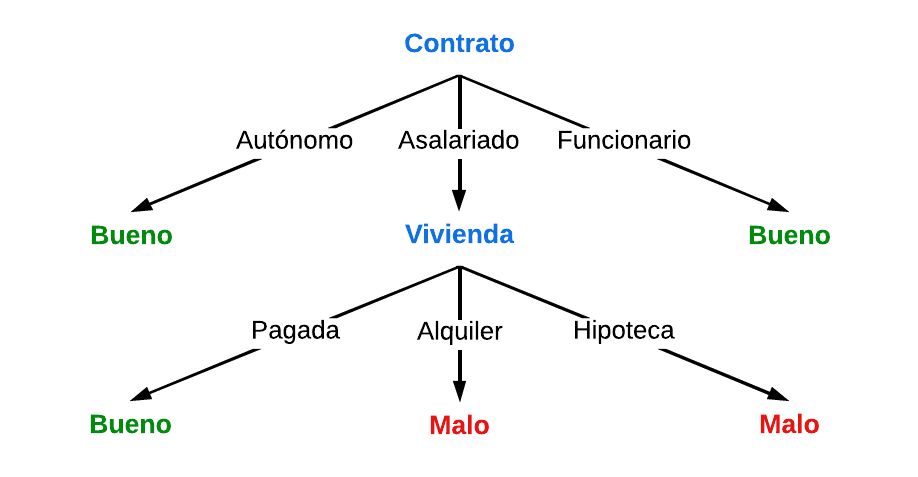
Cuando se quiera utilizar el sistema, lo único que hay que hacer es descender por los nodos siguiendo la rama del atributo con el valor correspondiente en cada caso.
El paso crítico en la construcción de un árbol de clasificación es el elegir en cada iteración el atributo más representativo para obtener una mejor generalización. La razón fundamental es que cuanto más sencillo sea un árbol capaz de separar los ejemplos de entrenamiento, menor es el riesgo de que se sobreajuste.